Scalable ICHRA software architecture: Backend infrastructure and design patterns for 2025
Published on December 01, 2025
By: Ideon

Introduction: Building Backend Systems for ICHRA at Scale
Every backend engineer faces the same decision: build a brittle, custom ICHRA stack – or architect a platform that processes thousands of real-time contribution calculations, manages multi-state compliance, and never blinks during open enrollment.
ICHRAs demand more than simple reimbursement logic. You need backend infrastructure that orchestrates carrier integrations, automates compliance tracking, and normalizes data across distributed services. The wrong design puts you behind: manual data entry, downtime during peak periods, and costly rewrites when regulations shift.
Modern ICHRA software architecture is microservices-first, event-driven, and built on API-first design patterns. This is how leading platforms support 50,000+ employees and deliver 99.9% uptime when it matters most.
Your infrastructure choices determine if you ship multi-carrier, multi-state functionality in weeks – or watch competitors capture market share while you debug legacy code. The most scalable platforms use architectural patterns like event sourcing for audit trails, CQRS for scale, saga workflows for automation, and circuit breakers for real-world reliability.
The foundation: a backend built for speed, resilience, and compliance, ready for 10x growth.
Core ICHRA Software Architecture Patterns
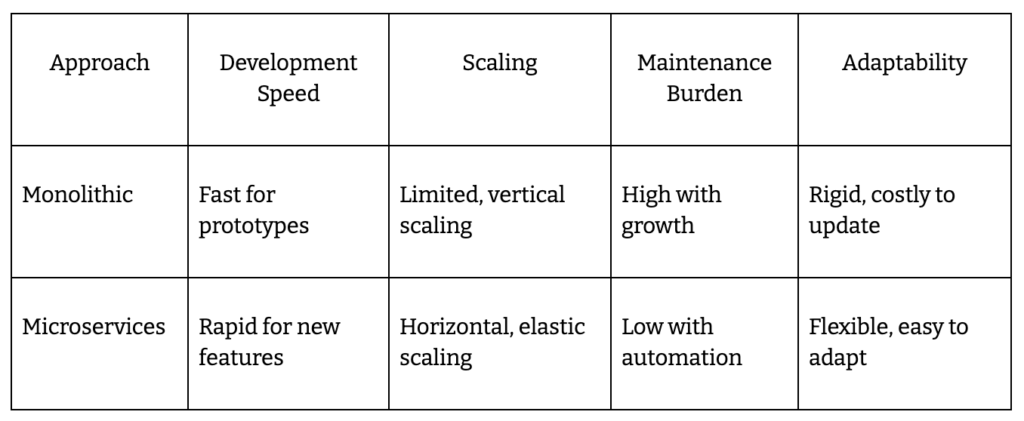
Your architecture is the difference between scaling to 50,000 employees or getting buried in maintenance tickets. Modern ICHRA platforms skip the monolith – they use microservices, event-driven patterns, and API-first design to move faster than custom builds.
Key architecture patterns that put you ahead:
- Event sourcing: Every contribution and reimbursement transaction is stored as an immutable event, providing full audit trails for compliance and supporting time-based queries.
- CQRS (Command Query Responsibility Segregation): Separates write logic (contributions, enrollments) from read models (reporting, dashboards), optimizing both for speed and scale.
- Saga pattern: Orchestrates long-running, multi-step workflows like enrollments across distributed services, handling failures and rollbacks automatically.
- Circuit breakers: Shield your system from slow or failing carrier and payroll APIs, maintaining uptime when external dependencies falter.
Core infrastructure pillars for ICHRA scalability:
- Distributed, parallel contribution processing across employee populations
- Real-time compliance validation for ACA, ERISA, and IRS rules
- Automated reimbursement workflows to minimize manual intervention
- Multi-tenant data isolation for security and customer segmentation
Choosing the right architecture sets the pace for your roadmap – outpacing custom builds and adapting as regulations or carrier requirements evolve. The wrong foundation slows every release, multiplies compliance risks, and keeps you in catch-up mode while API-first competitors ship faster.
API-Driven Reimbursement Processing Architecture
Reimbursement Workflow Engine Design
Scaling ICHRA reimbursement demands an engine that never stalls – no matter how many claims hit at once. Asynchronous processing queues absorb spikes and keep workflows moving. Orchestrate each reimbursement with a state machine: every request transitions through submitted, validated, approved, processed, paid, and audited. If an external service fails, apply retry logic with exponential backoff. When retries run out, route the event to a dead letter queue for remediation.
javascript
// Example: State machine transition for reimbursement request
switch (request.state) {
case ‘SUBMITTED’:
// Validate eligibility
request.state = ‘VALIDATED’;
break;
case ‘VALIDATED’:
// Calculate contribution
request.state = ‘APPROVED’;
break;
case ‘APPROVED’:
// Route payment
request.state = ‘PROCESSED’;
break;
case ‘PROCESSED’:
// Mark as paid
request.state = ‘PAID’;
break;
case ‘PAID’:
// Log audit entry
request.state = ‘AUDITED’;
break;
}
API Layer Architecture
API Layer Architecture
RESTful endpoints power fast submission and status checks, while GraphQL supports complex reporting and dashboard queries. Webhooks push real-time updates back to clients. Rate limiting and throttling protect uptime when clients or partners misbehave. Idempotency keys stop duplicate payouts from repeated client retries.
Processing Pipeline Components
- Eligibility validation service
- Contribution calculation engine
- Payment routing service
- Audit trail generator
Backend Performance Optimizations
- Database connection pooling
- Redis caching for frequent eligibility lookups
- Batch processing of high-volume claims
- Horizontal scaling for peak open enrollment periods

Batching, caching, and scaling let you process thousands of claims in parallel while keeping API response times predictable – no matter how many clients are shipping.
Database Design and Data Flow Optimization
Core Database Schemas
Shipping scalable ICHRA platforms means building schemas that don’t buckle under peak enrollment. Start with tables for employee eligibility, contribution tracking, reimbursement transactions, and compliance audits. Each must handle rapid updates and high-volume queries.
Example: Employee eligibility table for fast lookups and easy event sourcing.
sql
CREATE TABLE employee_eligibility (
employee_id UUID PRIMARY KEY,
class_id UUID NOT NULL,
status VARCHAR(16) NOT NULL,
effective_date DATE,
end_date DATE
);
CREATE INDEX idx_eligibility_class ON employee_eligibility(class_id);
Data Flow Architecture
Real-time sync is non-negotiable. Use change data capture (CDC) to trigger downstream processes instantly when a record changes. Event streaming platforms like Kafka or Pulsar push updates to analytics and reporting warehouses. Archive old data with GDPR-compliant retention rules to keep storage lean and compliant.
- CDC for instant eligibility and contribution updates
- Event streaming for audit trails and analytics
- Data warehousing for reporting, with automated retention policies
Optimization Strategies
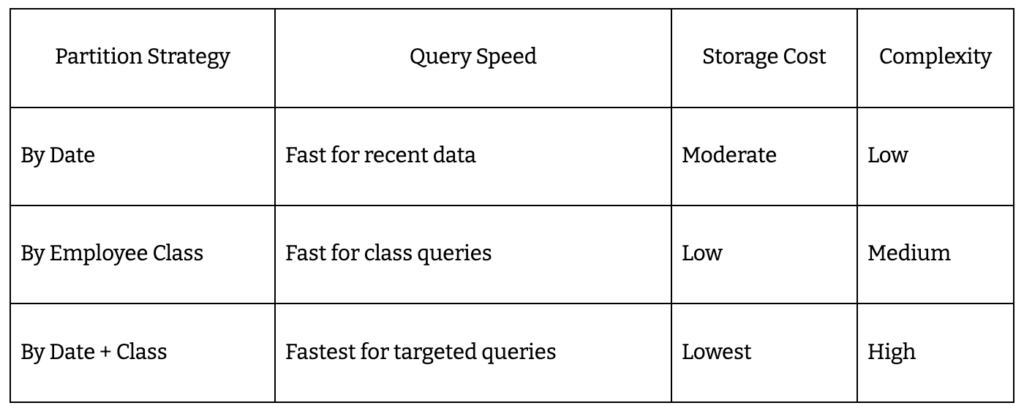
Partition by date and employee class to keep queries fast, even at scale. Index contribution tables for rapid eligibility and reimbursement lookups. Read replicas handle heavy reporting loads without slowing transaction speed. Archive historical transactions to cold storage.
- Partitioning by month or employee class
- Secondary indexing for contribution_id
- Read replicas for analytics queries
- Archive tables for records older than 2 years
Performance Considerations
Optimize queries and manage connection pools to survive open enrollment surges. For time-series contribution history, use specialized indexes or Postgres BRIN index for massive tables. Choose normalized schemas for perfect data integrity, or denormalize where speed trumps redundancy. Cloud-native databases like Aurora or Cloud SQL bring autoscaling and automated failover – critical for zero downtime in production.
Compliance Tracking and Automated Workflows
Compliance Engine Architecture
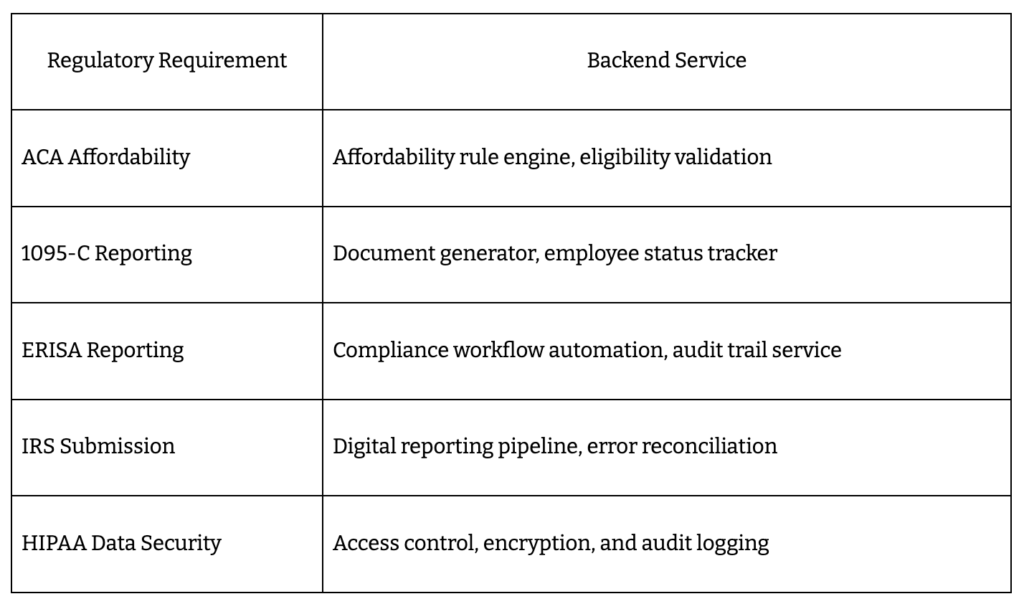
Move faster than manual audits ever could. Embed a compliance engine that automates ACA affordability checks, 1095-C generation, ERISA reporting, and IRS submissions – so every step is covered as your platform scales.
- Rule engines for ACA safe harbor calculations
- Automated 1095-C/1094-C document generation
- ERISA workflow orchestration
- IRS reporting and digital submission pipelines
Workflow Automation Patterns
Manual compliance is a bottleneck – event-driven automation isn’t. Trigger compliance checks and reporting as soon as data changes, not at the end of the month.
- Event-driven compliance validation
- Batch scheduling for large-scale document generation
- Automated error handling and remediation
- Immutable audit trail creation for every compliance event
Backend Validation Systems
Trusting stale spreadsheets risks fines. Build validation into every contribution and eligibility update.
- Affordability calculation based on federal poverty levels and regional data
- Employee class and eligibility checks
- Contribution limit enforcement
- Multi-state and cross-jurisdiction compliance verification
python
# Affordability check example (ACA 9.12% rule for 2025)
def is_affordable(monthly_premium, household_income):
return (monthly_premium / (household_income / 12)) <= 0.0912
Monitoring and Observability
Spot compliance risks before auditors do. Real-time dashboards and alerts keep your ops team ahead.
- Compliance dashboard APIs for real-time metrics
- Error logging and alerting for failed checks
- Performance analytics on workflow completion
- Regulatory update notifications for new rules or thresholds
Integration Strategies for Carrier and Payroll Systems
Carrier Integration Architecture
Every extra carrier integration is a drag on your roadmap. API gateways manage multiple carrier connections through a single, unified entry point. Protocol adapters handle legacy EDI, modern FHIR, and REST – so you avoid rebuilding for every carrier’s quirks. Data normalization layers convert messy carrier payloads into a common schema, while fallback logic routes requests around downtime.
Payroll System Connectivity
Payroll data powers eligibility and contributions, but every provider speaks a different language. Use a hybrid of SFTP batch uploads and real-time APIs to sync employment data. Map and transform incoming files or payloads to your backend schema. Automate error reconciliation – catch mismatches and missing fields before they hit your compliance stack.
Backend Integration Patterns
Distributed integrations need patterns that survive failures and scale:
- Publisher-subscriber messaging to decouple services
- Request-response with timeout logic for slow or unreliable endpoints
- Compensation transactions to unwind partial updates
- Idempotency keys to prevent duplicate processing
python
# Idempotency handler for reimbursement submission
if is_already_processed(request_id):
return get_previous_response(request_id)
else:
response = process_new_submission(payload)
save_response(request_id, response)
return response
javascript
// Circuit breaker pattern for carrier API calls
if (circuitBreaker.isOpen()) {
throw new Error(“Carrier API unavailable”);
}
try {
carrierApi.call(payload);
circuitBreaker.success();
} catch (e) {
circuitBreaker.failure();
// fallback or retry logic here
}
Security and Reliability
Security isn’t optional. Use mTLS for carrier connections, OAuth 2.0 for payroll APIs, and encrypt all data in transit and at rest. Circuit breakers protect your uptime when partners fail or slow down.
Real-World Architecture Case Studies
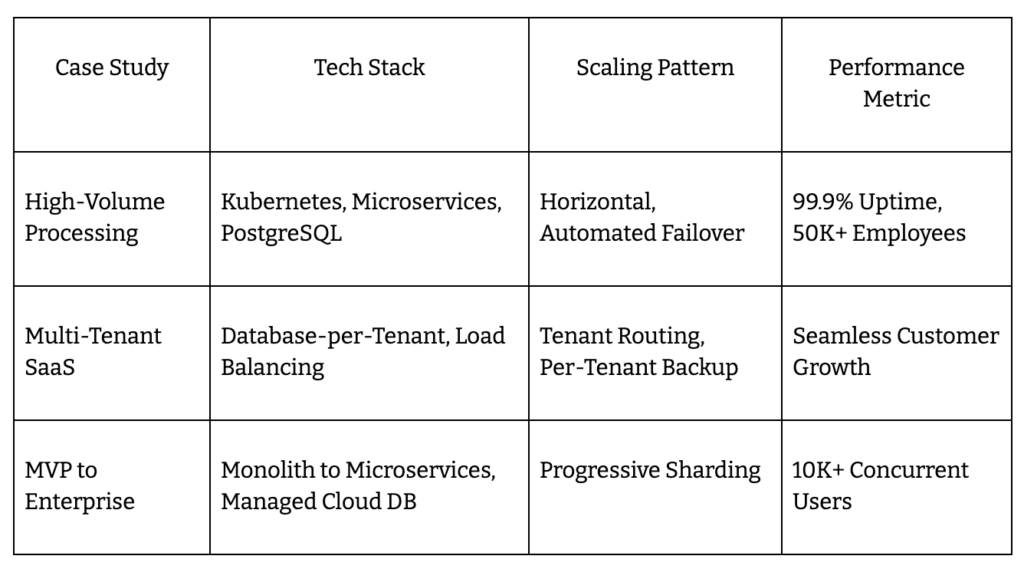
High-Volume Processing Platform
Fast-growing ICHRA platforms can’t afford downtime. One leading system scaled to 50,000+ employees across 15 states using a microservices architecture on Kubernetes. PostgreSQL, bolstered with read replicas, kept data synchronized and responsive. Peak open enrollment saw 99.9% uptime, with horizontal scaling absorbing traffic spikes and automated failover eliminating single points of failure.
Multi-Tenant SaaS Architecture
Handling dozens of employer groups on a single codebase, this SaaS model isolates each client’s data with a database-per-tenant strategy. A shared service layer uses intelligent tenant routing and load balancing to keep resource contention low. Per-tenant backup and restore routines drive compliance and reduce risk. Horizontal scaling lets platforms add customers without architectural rewrites.
Startup MVP to Enterprise Scaling
A benefits tech startup launched with a monolithic MVP, then migrated to microservices as demand surged. Cloud-native deployment (containerized services, managed databases) allowed progressive sharding and quick performance tuning. Migrating incrementally, the team fixed scaling bottlenecks before they became critical, enabling the platform to hit 10,000+ concurrent users during busy periods
Performance Optimization and Scaling Strategies
Backend Performance Techniques
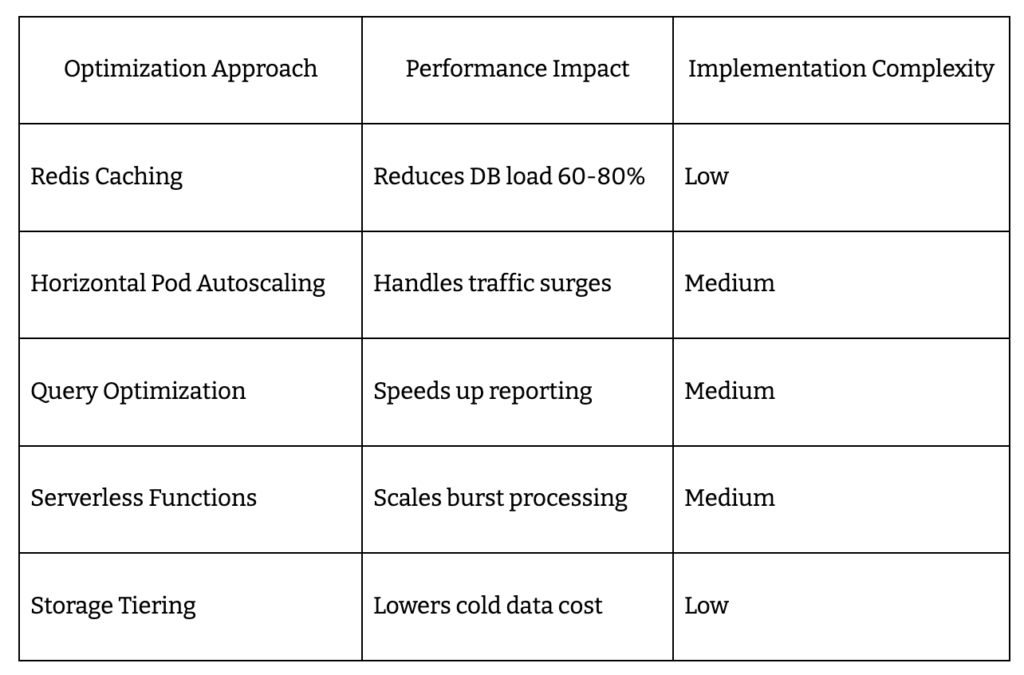
Speed wins. Platforms using Redis or Memcached caching slash database load by up to 80% on eligibility and contribution queries. Asynchronous processing queues absorb spikes – batch-heavy reimbursement jobs won’t bottleneck real-time APIs. Use a CDN for static resources so your core services never slow down for asset delivery.
python
# Redis caching for employee eligibility
def get_eligibility(employee_id):
cached = redis.get(employee_id)
if cached:
return cached
data = db.query(employee_id)
redis.set(employee_id, data, ex=86400)
return data
Scaling Architectural Patterns
Horizontal pod autoscaling keeps you ahead of traffic surges. Deploy Kubernetes HPA to adjust capacity based on CPU, memory, or queue depth. Database connection pooling and load balancer tuning prevent bottlenecks as user count climbs. Distribute your stack across regions to minimize latency for national employers.
yaml
# Kubernetes Horizontal Pod Autoscaler example
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
spec:
scaleTargetRef:
kind: Deployment
name: reimbursement-api
minReplicas: 4
maxReplicas: 50
metrics:
– type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 65
Monitoring and Optimization
Application performance monitoring (APM), database query analysis, and real-time API response tracking reveal bottlenecks before customers do. Set resource utilization alerts to catch runaway usage or failed autoscaling.
Cost Optimization Approaches
Reserve cloud instances for predictable workloads, adopt serverless for bursty tasks, and tier storage to cut costs. Monitor network bandwidth and right-size infrastructure to avoid overpaying for idle capacity.
Common Technical Challenges and Solutions
Data Consistency Challenges
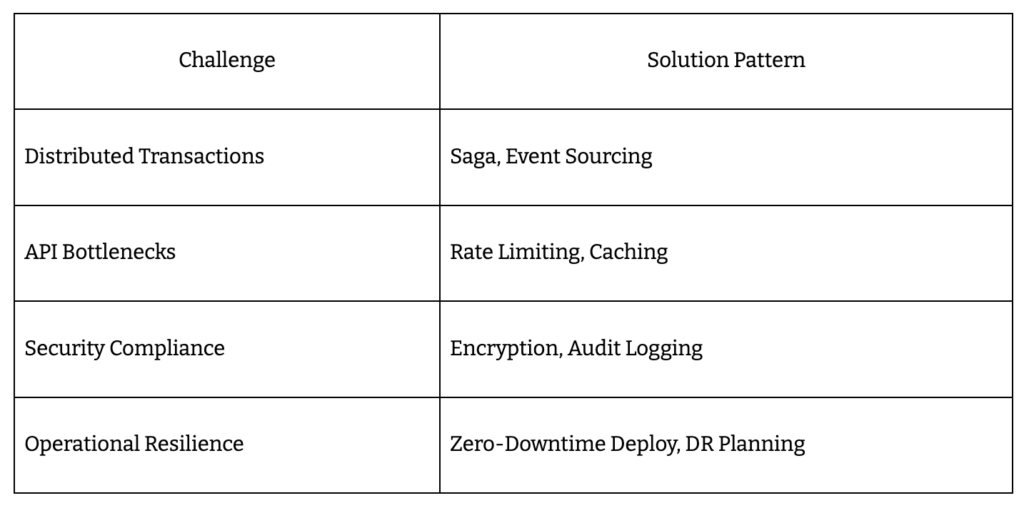
Distributed ICHRA systems break if transactions fall out of sync. Multi-system updates – across carriers, payroll, and compliance – demand bulletproof patterns for consistency.
- Use event sourcing for every reimbursement and eligibility event: every change is logged, providing a full audit trail.
- Apply saga patterns for distributed transactions, coordinating updates and compensations when steps fail.
- Implement conflict resolution strategies for eventual consistency – last-write-wins or versioned updates.
python
# Saga pattern for distributed reimbursement
def process_reimbursement(event):
try:
debit_account(event)
update_carrier(event)
log_audit(event)
except Exception:
compensate_transaction(event)
Performance Bottlenecks
Every millisecond counts when processing thousands of ICHRA contributions. Bottlenecks stop platforms cold during open enrollment.
- Alleviate database lock contention with row-level locking and partitioned tables.
- Set API rate limits and retry logic to avoid overload and ensure reliability.
- Prevent memory leaks with automated profiling and container limits.
- Minimize network latency by deploying services regionally.
Security and Compliance Issues
HIPAA and SOC 2 aren’t optional – missing requirements means lost deals and regulatory risk.
- Encrypt all PHI at rest and in transit.
- Enforce strict access controls and audit logging for sensitive actions.
- Prepare for SOC 2 with automated vulnerability scans and penetration testing.
- Track every access and change for HIPAA audit readiness.
Operational Challenges
Downtime during open enrollment is a dealbreaker. ICHRA platforms must be built for resilience.
- Deploy zero-downtime strategies with blue/green or rolling updates.
yaml
# Kubernetes rolling update configuration
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 0
maxSurge: 1
- Schedule automated backups and disaster recovery drills.
- Build incident response playbooks for rapid rollback and recovery.
Conclusion: Your Backend Architecture Implementation Roadmap
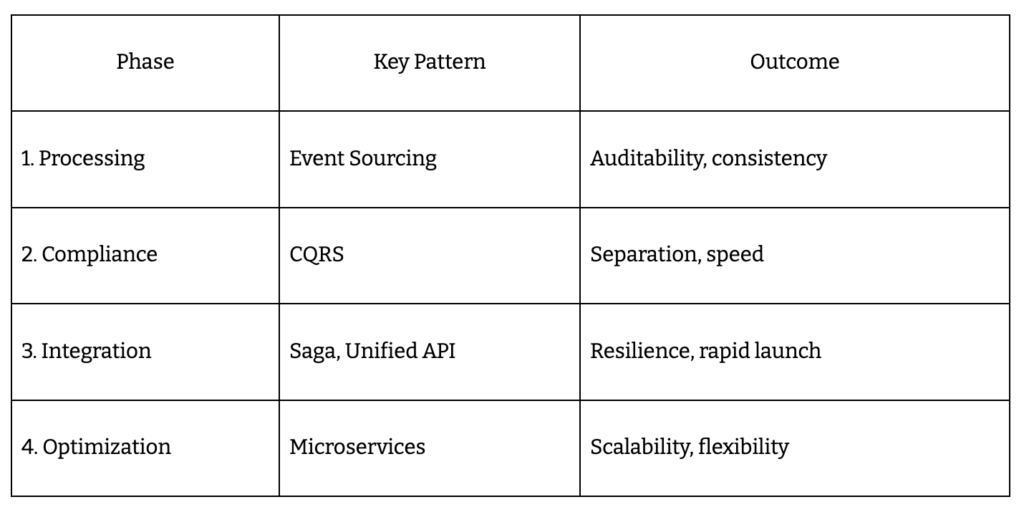
Move fast or watch competitors capture the market. Scalable ICHRA software architecture starts with event-driven, API-first, compliance-ready design – anything less slows you down. The winning roadmap looks like this:
- Build core reimbursement processing first – get the engine running before layering complexity.
- Add compliance automation next, so you never scramble when regulations shift.
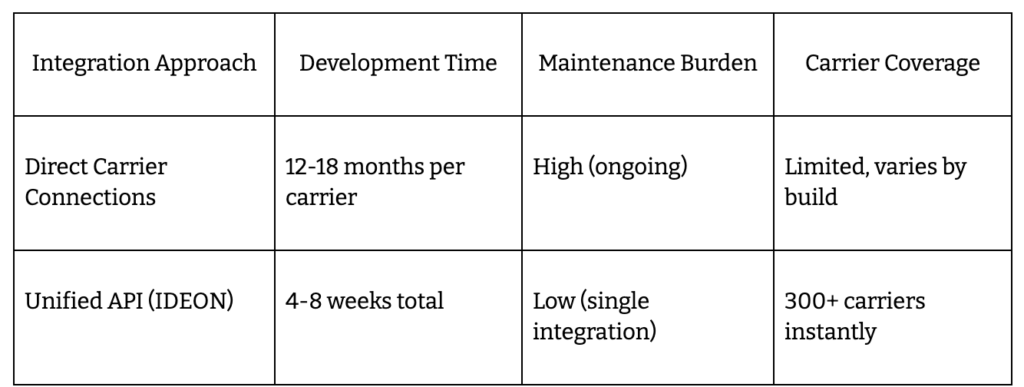
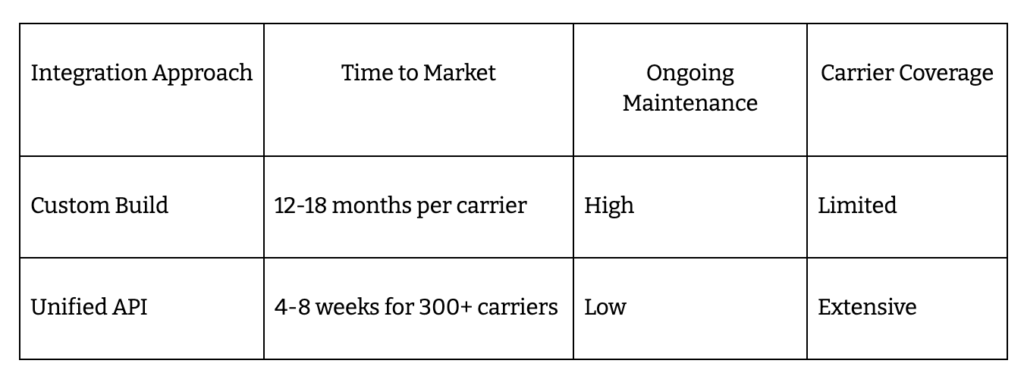
- Integrate with carriers and payroll using unified APIs like IDEON, cutting 18 months down to 4-8 weeks.
- Optimize for scale: implement event sourcing, CQRS, saga patterns, and microservices for reliability and agility.
Is your backend architecture built to handle 10x growth, or will you be left watching others ship first? Every technical decision you make right now will define your platform’s ability to outpace custom development for years to come.
Technical FAQs: ICHRA Backend Architecture
What technology stack sets you up to outpace custom builds?
Go with a modern stack: Node.js, TypeScript, or Go for service logic; Kubernetes for orchestration; PostgreSQL or Aurora for relational data. Pick tools that support rapid iteration, cloud-native deployment, and strong API support. Don’t get stuck with legacy stacks that slow every release cycle.
Microservices or monolith for ICHRA?
Microservices win as soon as you hit scale. Decompose by business domain – eligibility, contributions, reimbursements, compliance. Each service scales and deploys independently, so you’re never held back by a single bottleneck. Monoliths work for MVPs but cost you speed and flexibility when regulations or carriers change.
Which database fits ICHRA: PostgreSQL, MySQL, or NoSQL?
Relational is non-negotiable for compliance and financial accuracy. PostgreSQL is the go-to: robust, transactional, open-source, and cloud-optimized. Reserve NoSQL for edge use-cases – logging, analytics, or unstructured event storage. For high-volume workloads, use read replicas and partitioning to keep queries fast.
How do you manage distributed transactions across carrier and payroll integrations?
Forget multi-phase commits; use saga patterns for long-running, multi-system updates. Each step triggers the next, and failed steps are compensated with explicit rollback logic. Log every state change as an immutable event, so you never lose the audit trail.
Build custom carrier integrations or use a unified API?
A unified API like IDEON skips 18 months of custom engineering. You connect once, unlock 300+ carriers, and stay focused on product – not plumbing. Direct builds mean endless maintenance and slow onboarding. Unified APIs ship new carriers in weeks, not quarters.
What’s required for HIPAA and SOC 2 compliance?
Encrypt PHI at rest and in transit. Enforce RBAC for every service. Automate audit logging of access and changes. Run regular vulnerability scans and have incident response protocols in place. SOC 2 means continuous monitoring and documented controls – make this part of your CI/CD pipeline.
How do you optimize backend performance for ICHRA?
Cache eligibility and plan lookups with Redis to cut database load by up to 80%. Batch process reimbursements to flatten traffic spikes. Use asynchronous queues for non-blocking workflows. Monitor for slow queries and refactor hot paths before they become bottlenecks.
How do you design for horizontal scaling and high availability?
Deploy services as containers on Kubernetes with autoscaling policies. Use health checks and rolling updates for zero downtime. Spread workloads across regions to cut latency for national employers. Read replicas and multi-zone databases keep you online if a region drops.
Which monitoring and observability tools matter most?
Stack your monitoring: Prometheus for metrics, Grafana for dashboards, ELK or OpenSearch for logs, and distributed tracing (Jaeger, Zipkin) for debugging. Alert on error rates, latency spikes, and resource saturation – catch issues before customers do.
How do you implement zero-downtime deployments?
Use blue/green or rolling deployment strategies. Automate rollback on health check failures. Always deploy behind a load balancer, and keep database migrations backward-compatible to avoid breaking running services during cutovers.